AI Daily Digest — 2026-04-07
Anthropic's Most Powerful Model Is Intentionally Locked Away · Anthropic's Revenue Just Jumped $11 Billion in a Single Month · A Massive Open-Source AI Model Just Dropped From China


1. One Thing to Tell Your Friends
Anthropic built what may be the most powerful AI model ever created — and deliberately chose not to release it to the public. Instead, only 12 research organizations can access it, under strict agreements, specifically for cybersecurity work. The reason: in testing, it generated 181 working browser exploits. That's a sign the AI industry is starting to wrestle seriously with the question of whether some tools are simply too dangerous to share openly.
2. Top Stories
Anthropic's Most Powerful Model Is Intentionally Locked Away
Anthropic built a model so capable at hacking that they've restricted it to 12 vetted cybersecurity research partners — and have no plans to release it publicly.
The project is called Project Glasswing, and the model is called Claude Mythos Preview. It was announced today not as a product launch, but as a deliberate non-release. This is unusual — AI labs almost always release or widely license their best models. Anthropic made the opposite call.
- Scored 83.1% on CyberGym, a specialized cybersecurity skills benchmark
- Generated 181 working Firefox browser exploits in red-team testing (the previous model generated 2)
- $104 million in commitments from the 12 partner organizations
- 862 upvotes and 385 comments on Hacker News
- Cybersecurity assessment report and System Card PDF available
The gap between 2 exploits and 181 is the key number here. That's not a gradual improvement — it's a qualitative leap in capability. Tech commentator Simon Willison called the restriction "justified." The 12 partners all signed agreements governing how they can use the model.
What this means for you: This is the first major example of an AI lab proactively restricting their most capable model rather than racing to release it. If this pattern catches on — or if it doesn't — that decision will shape how dangerous AI capabilities get distributed over the coming years.
Anthropic's Revenue Just Jumped $11 Billion in a Single Month
Anthropic went from $19 billion in annual revenue in March 2026 to $30 billion in April 2026 — overtaking OpenAI's reported $24 billion figure.
Annual Recurring Revenue (ARR) is a way of measuring how much money a company makes per year, based on its current monthly rate. It's the standard yardstick for subscription and API (software access) businesses. Anthropic's $11 billion single-month jump is, by any measure, extraordinary. One analyst is projecting $90 billion ARR by the end of 2026.
- $30B ARR as of April 2026 (up from $19B in March)
- Surpasses OpenAI's reported $24B ARR
- Revenue comes from Claude subscriptions and API access (businesses paying to use Claude in their own products)
- Source: Latent Space
This growth is being driven by businesses embedding Claude into their own products — not just individuals paying for subscriptions. Enterprise adoption tends to compound quickly once it starts.
What this means for you: The AI industry is generating real money at a scale that will sustain continued heavy investment in research and development. Anthropic's growth specifically funds more work on safety-focused AI — which matters given stories like Project Glasswing above.
A Massive Open-Source AI Model Just Dropped From China
Z.ai, a Chinese AI lab, released GLM-5.1 — a 754-billion-parameter open-weights model under an MIT license, meaning anyone can download and run it.
"Parameters" are roughly analogous to the number of adjustable settings in an AI model — more parameters generally means more capability, but also more computing power required to run. At 754 billion parameters, this is enormous. The model weighs 1.51 terabytes. For comparison, a standard laptop hard drive is typically 500GB to 1TB. This is a serious piece of infrastructure.
- 754 billion parameters, 1.51TB model size
- 58.4% score on SWE-Bench Pro (a coding benchmark where AI tries to solve real-world software bugs)
- MIT license — commercial use is allowed with no restrictions
- Available on HuggingFace (a platform for sharing AI models)
- 471 upvotes on r/LocalLLAMA
- More analysis: Simon Willison's blog
The significance here is the license. Most cutting-edge models are either proprietary (you pay for access) or open but restricted. MIT license means businesses and researchers can build on this freely.
What this means for you: Open models at this capability level give organizations — including governments, hospitals, and small companies — access to frontier AI without depending on US tech companies. The geopolitical implications are significant.
Claude Code Is Thinking Less, and Nobody Knows Why
A Hacker News thread with 1,169 upvotes on Reddit documents an approximately 67% drop in Claude Code's "thinking depth" following updates in February 2026. Anthropic has not responded.
"Thinking depth" refers to how extensively an AI reasons through a problem before giving an answer. Claude Code is Anthropic's AI tool for software development. Users are reporting that it's giving shallower answers — less thorough analysis, fewer steps worked through — than it did before February.
- ~67% reduction in reasoning depth documented by community
- Discussion thread: Hacker News
- Originated from r/ClaudeAI with 1,169 upvotes
- Anthropic has not publicly commented
The community is split on what happened. One theory: Anthropic deliberately reduced the amount of "thinking" the model does to save computing costs (thinking deeply costs more to run). Another theory: it's an accidental regression — a bug introduced by updates.
What this means for you: If you use Claude Code professionally, your experience may have changed since February without explanation. And more broadly: AI capabilities can quietly regress between updates, with no announcement. The companies building these tools are not obligated to disclose performance changes.
Anthropic Cuts Off Claude Subscriptions From Third-Party Tools
Anthropic has blocked Claude subscriptions from working with third-party tools like OpenClaw, forcing users to switch to pay-as-you-go API access or provide their own API keys.
OpenClaw is a popular third-party interface for using Claude. Many users preferred it for workflow features the official Claude interface doesn't offer. API (Application Programming Interface) access means paying directly per query rather than a flat monthly fee — which is often significantly more expensive for heavy users.
- Thousands of OpenClaw users affected
- Source: Ben's Bites
This follows earlier this week's reports (from the April 4-5 digests) of OpenClaw being deployed inside companies without IT oversight and raising security concerns. It's unclear whether Anthropic's restriction is a direct response to those concerns or a separate business decision.
What this means for you: If you use Claude through any third-party tool other than the official interface, check whether your workflow still functions. This is also a reminder that AI companies can change what their products do at any time — and your preferred setup may stop working without warning.

3. Trends & Themes
Theme 1: AI Capability Is Outrunning Distribution Decisions
The biggest story today — Project Glasswing — isn't really about a model. It's about a new kind of decision: what do you do when your AI is too powerful to safely release? The 181-exploit jump (vs. 2 for the prior model) is a data point, not just an anecdote. Meanwhile, GLM-5.1 is going in the opposite direction — fully open, no restrictions, anyone can download it. These two releases on the same day represent the two poles of a debate that will define the next few years.
Why this matters to you: Depending on which approach wins — restricted or open — the AI tools you have access to, and who controls them, will look very different.
Theme 2: The Reliability Problem Is Getting Louder
The Claude Code thinking regression (see Top Stories) is part of a broader pattern. AI models change constantly. Capability scores go up on benchmarks, but real-world performance on specific tasks can quietly degrade. The SWE-EVO benchmark result (covered in Research & Models below) reinforces this: models that score 72.8% on standard tests drop to 25% on longer, more realistic tasks.
Why this matters to you: If you're making professional decisions based on AI output, you need to know that the tool you're using today may perform differently next month — and that you'll likely not be told.
Theme 3: The AI Arms Race Is Now Also an Economics Race
Anthropic's $30B ARR milestone and the OpenClaw restriction are both business moves. So is Google cutting Veo 3.1 Lite video generation costs in half (see Business & Industry) — a direct response to OpenAI's Sora exit. The companies competing in AI are now competing on price, availability, and distribution terms, not just raw capability. The winner won't necessarily be the most capable model — it'll be the one that's most deeply embedded in workflows.
Why this matters to you: The AI tool you use in two years will likely be determined less by which is smartest and more by which company locked in the best business relationships.
Theme 4: AI Cheating Is Restructuring Classrooms in Real Time
Professors are posting in waves about what's happening in their classrooms right now (see GenAI in Education). It's not a future concern — it's happening today, affecting attendance, class participation, and the fundamental meaning of assignment completion. Multiple independent posts, from multiple disciplines, all this week.
Why this matters to you: If you teach, manage, or are enrolled in any educational program, the norms for what counts as student work are actively being renegotiated. There is no consensus yet.
Theme 5: Tiny Teams, Enormous Output
The Extreme Harness Engineering story (see Developer Tools) — one engineer, zero human-written code, 1 million lines, 1 billion tokens per day — and the Polymarket bot story ($313 to $438,000 in 30 days, 2 prompts, 40 minutes of setup) point to a consistent signal: AI is dramatically compressing what small groups of people can produce. These aren't isolated cases.
Why this matters to you: The economic moat that comes from having a large team — or from simply putting in more hours — is shrinking. What's increasingly valuable is knowing what to build and how to direct AI to build it well.
4. Creative AI & Media
ACE-Step 1.5 XL arrives with turbo, base, and fine-tuned variants for music generation.
ACE-Step is an AI model for generating original music from text descriptions. The new XL version uses a 4-billion-parameter Diffusion Transformer (DiT) — an architecture originally developed for image generation, now applied to audio. Three variants were released: turbo (fast), base (balanced), and SFT (fine-tuned for quality).
- 4 billion parameter DiT architecture
- Three variants: turbo, base, SFT (supervised fine-tuning — trained further on high-quality examples)
- Available on HuggingFace
- 72 upvotes on r/LocalLLAMA
What this means for you: If you create content — videos, podcasts, games — AI music generation is maturing quickly. Tools like ACE-Step can produce original, usable music from a text description. The "turbo" variant specifically targets low-latency generation, which matters for real-time or iterative creative work.
Google cuts Veo 3.1 Lite video generation API costs in half as Sora exits the market.
Veo is Google's AI video generation model. The 3.1 Lite variant is a smaller, cheaper version optimized for API access (businesses using it programmatically). The price cut comes immediately after OpenAI announced Sora — their video generation product — is exiting. That's not a coincidence.
- API cost reduced by 50%
- Source: 9to5Google
What this means for you: AI video generation just got cheaper for developers building products. If you've been watching AI video tools and waiting for costs to come down, that's happening.
5. Developer Tools & Infrastructure
One engineer. Zero human-written code. One million lines. Five months.
Ryan Lopopolo, an engineer at OpenAI, built a production product over five months using exclusively AI-generated code — no human-written lines. The system processes 1 billion tokens (roughly 750 million words) per day. Total team size: 3 people.
- 1 million lines of code, 0 human-authored
- 1 billion tokens/day processed
- 3-person team total
- 5-month build timeline
- Source: Latent Space
This isn't a demo or an experiment. It's a running production system. The story challenges the assumption that AI-assisted code is somehow "lesser" or requires constant human correction.
What this means for you: The skill of directing AI to write good software is becoming as important as the skill of writing software yourself. The bottleneck is shifting from "can you code?" to "do you know what to build?"
Try it: The next time you have a small software task, try describing it entirely in plain English to an AI coding tool before writing a single line yourself. Notice where it succeeds and where you need to correct it.
Google open-sourced Scion, an experimental testbed for multi-agent AI systems.
"Multi-agent" means multiple AI models working together, each handling different parts of a task. Scion is Google's research tool for testing these systems. It runs agents in isolated containers (sandboxed environments that can't affect the host system) and supports both local and remote execution.
- 154 upvotes on Hacker News
- Source: InfoQ
What this means for you: As AI systems get more complex — with multiple models collaborating — tools for safely testing and understanding those systems become critical infrastructure. Google making this open-source accelerates research across the industry.
SpectralQuant beats Google's TurboQuant by 18.6% with 2.2x latency speedup.
KV cache compression is a technique for reducing how much memory an AI model needs while running — the "KV cache" (Key-Value cache) stores intermediate computations. TurboQuant, released by Google, was last week's leading method. SpectralQuant, from Dynamis Labs, has already surpassed it.
- 18.6% improvement over TurboQuant
- 2.2x latency speedup (responses arrive more than twice as fast)
- 70 upvotes on r/LocalLLAMA
- Source: GitHub
What this means for you: Faster, cheaper AI inference (the process of getting a response from a model) makes AI more accessible on lower-end hardware and reduces costs for businesses running AI at scale.
M5 Max serving 1 billion tokens per day locally — community shares results.
Apple's M5 Max chip is powerful enough to serve AI at production scale from a single machine. An r/LocalLLAMA thread (84 upvotes) documents community members achieving 1 billion tokens per day throughput without cloud infrastructure.
What this means for you: "Local AI" — running models on your own hardware, without sending data to an external server — is becoming viable at meaningful scale. For privacy-sensitive use cases, this matters significantly.
6. Research & Models
SWE-EVO reveals a major hidden weakness in coding agents.
The SWE-EVO benchmark tests AI coding agents on long-horizon tasks — not just fixing a single bug, but sustaining productive software development over many steps. The results reveal a sharp cliff:
- Standard SWE-Bench score: 72.8%
- SWE-EVO long-horizon score: 25%
- Paper: arXiv
A "coding agent" is an AI that can not only write code but execute it, read error messages, and iterate. The drop from 72.8% to 25% is significant: the models are good at isolated tasks, but struggle to maintain context, coherence, and quality over extended projects. This has real implications for claims about fully AI-generated codebases.
SPHINX benchmark: even GPT-5 scores only 51.1% on visual reasoning.
SPHINX tests the ability of AI models to reason about what they see — not just describe images, but draw inferences from visual information. GPT-5 scoring 51.1% means it gets roughly half of these tasks wrong.
What this means for you: Visual reasoning remains a genuine limitation for frontier AI. Applications that require AI to interpret charts, diagrams, or complex visual scenes should be validated carefully.
TriAttention achieves 10.7x KV memory reduction and 2.5x throughput improvement.
TriAttention is a new attention mechanism — "attention" is the core mathematical operation in modern AI models that lets them relate different parts of a text to each other. A 10.7x reduction in KV memory means models can handle much longer inputs on the same hardware. 2.5x throughput means twice as many responses in the same time on the AIME25 benchmark (a math reasoning test).
BioAlchemy brings reinforcement learning to biology research.
BioAlchemy is a dataset of 345,000 biology problems designed for reinforcement learning (a training method where an AI improves by getting feedback on its answers). The BioAlchemist-8B model trained on this data achieved a 9.12% benchmark gain. Biology is notoriously hard for AI because the reasoning chains are long and the factual domain is vast.
STORM models 1.2 million transcriptomic profiles across 18 organs.
Transcriptomics is the study of which genes are active in which cells at a given time. STORM is a multimodal (handles multiple data types) foundation model trained on 1.2 million such profiles, covering 18 different organ types. Foundation models are large pre-trained models that can be fine-tuned for specific tasks.
LLMs encode their own failures — and that signal can be used to route around them.
A new paper finds that AI language models internally encode a kind of "uncertainty signal" before they generate a wrong answer. By training lightweight probes (small detection models) on these signals, researchers achieved a 70% reduction in compute (processing costs) by routing easy questions to cheaper models and hard questions to expensive ones — before generating any output.
7. Business & Industry
A Polymarket bot turned $313 into $438,000 in 30 days with 2 prompts and 40 minutes of work.
Polymarket is a prediction market where users bet on real-world outcomes. Nate's Newsletter documents a case where someone built a trading bot using only 2 AI prompts and roughly 40 minutes of setup work. The bot found and exploited pricing inefficiencies that human traders had missed.
- $313 initial stake → $438,000 return
- 30-day window
- Setup time: ~40 minutes, 2 prompts
- Source: Nate's Newsletter
This is an extreme example, but the underlying point applies broadly: AI is rapidly closing information and speed gaps that used to require large teams or expensive expertise.
What this means for you: Markets — financial and otherwise — that depend on human-speed information processing are being disrupted. Freelancers still charging 2023 rates (as the newsletter notes) may find themselves undercut not by cheaper humans, but by AI-assisted competitors.
Iran struck AWS data centers in the UAE and Bahrain — the first military attack on private cloud infrastructure.
AWS (Amazon Web Services) is the world's largest cloud computing provider. Cloud infrastructure — the physical data centers that power AI services and most of the internet — has historically been treated as civilian infrastructure. This changes that.
- Targets: UAE and Bahrain AWS facilities
- Reported by: The Intercept
AI systems depend on stable cloud infrastructure. If data centers become routine military targets, the resilience assumptions underlying most AI services need to be reconsidered.
An 18,000-word New Yorker investigation asks: "Can Sam Altman Be Trusted?"
Ronan Farrow's investigation into OpenAI's CEO ran in The New Yorker. Zvi Mowshowitz, one of the most careful AI-industry commentators, read all 18,000 words and gave his verdict: No.
- Source: Zvi's Substack
This matters because OpenAI remains the highest-profile AI company in the world and Altman is its primary public voice on AI policy. Questions about trust and governance at that level have industry-wide implications.
8. GenAI in Education
There is no gentle way to say this: AI is currently dismantling traditional academic assessment, and the professor community is documenting it in real time.
Multiple independent threads on r/Professors this week paint a consistent picture:
- A professor told students exactly what to do with AI assistance — following the syllabus precisely — and they still failed (263 upvotes). The students didn't understand the material even with AI help.
- AI is changing classroom dynamics: students are watching TV during class (102 upvotes), apparently confident they can use AI to catch up later.
- One professor estimates 25% of submitted work in their class is AI-generated (104 upvotes).
- An art student submitted AI-generated work for an art class (67 upvotes) — a discipline where the process is arguably the point.
- One thread described what the community called the worst AI cheating case yet (94 upvotes).
These posts span multiple disciplines and institutional types. This is not a fringe concern — it's a widespread, active disruption.
The professor debate is splitting roughly into two camps:
Camp 1: Ban AI outright, design assessments that require in-person, handwritten, or demonstrably human work. Oral exams. Live coding. Process portfolios.
Camp 2: Integrate AI explicitly, teach students to use it well, and redefine what "learning" means in an AI-assisted world.
Neither camp has consensus. The tension reflects a genuine philosophical disagreement: is education about the process of struggling with hard things, or about demonstrating competence in outcomes?
What this means for you: If you are a student, the rules about what's acceptable are actively changing and vary widely by institution and instructor. Check. If you are a parent, the skills your children are developing — or not — in AI-assisted classrooms are genuinely uncertain. If you are an employer, credentials from 2026 onward carry new ambiguity about what a student actually learned.
9. Surprising & Under-the-Radar
MeowLLM: a 3.5-million-parameter cat-persona language model, trained from scratch, achieves 84.2% eval pass rate.
For context: GPT-4 has an estimated 1.8 trillion parameters. MeowLLM has 3.5 million — roughly 500,000 times smaller. The fact that a model this tiny achieves an 84.2% pass rate on its evaluation suite is genuinely surprising. It also only speaks as a cat.
- 42 upvotes on r/LocalLLAMA
- Purpose: apparently to be delightful
This sits at the intersection of "why did someone build this" and "the fact that this works tells us something interesting about how little compute is needed for narrow tasks."
Gemma 4 31B has 52 GGUF quantizations already ranked by quality.
GGUF is a file format for AI models designed to run efficiently on consumer hardware. "Quantization" means compressing the model by reducing the precision of its numbers — like converting a high-resolution image to a lower resolution to save space. The community already has 52 different compressed versions of the just-released Gemma 4 31B, ranked by how much quality each compression sacrifices.
- 252 upvotes on r/LocalLLAMA
- Winner: Unsloth UD-variants (best quality per gigabyte)
- Source: Local Bench Substack
The speed of community optimization is remarkable. A model releases; within days the community has profiled every compression tradeoff.
RASA: safety guardrails in Mixture-of-Experts AI models can be bypassed through routing manipulation.
Mixture-of-Experts (MoE) is an architecture where different "expert" sub-networks handle different types of queries. Standard safety testing may not catch vulnerabilities specific to how queries get routed between experts. The RASA paper shows these routing seams can be exploited even when top-level safety metrics look fine.
What this means for you: Safety ratings on AI models may not reflect the actual attack surface. This is primarily a concern for organizations deploying AI in sensitive contexts.
AI alignment demands standards from AI that humans don't meet — and humans face no accountability for that.
An essay making the rounds argues that AI alignment research (the field trying to make AI systems reliably safe and beneficial) holds AI to behavioral standards that no human institution meets, while the humans setting those standards are themselves unaccountable. The critique is pointed and has generated significant discussion.
- Source: Gynoid Gearhead Substack
Sensitive information can leak through AI reasoning chains — "Selective Forgetting" as a fix.
When AI models reason step-by-step before answering (as in OpenAI's o1-style models), sensitive information can appear in those intermediate steps even if it's not in the final answer. A new technique called "Selective Forgetting" targets this by training models to suppress sensitive content specifically in reasoning chains.
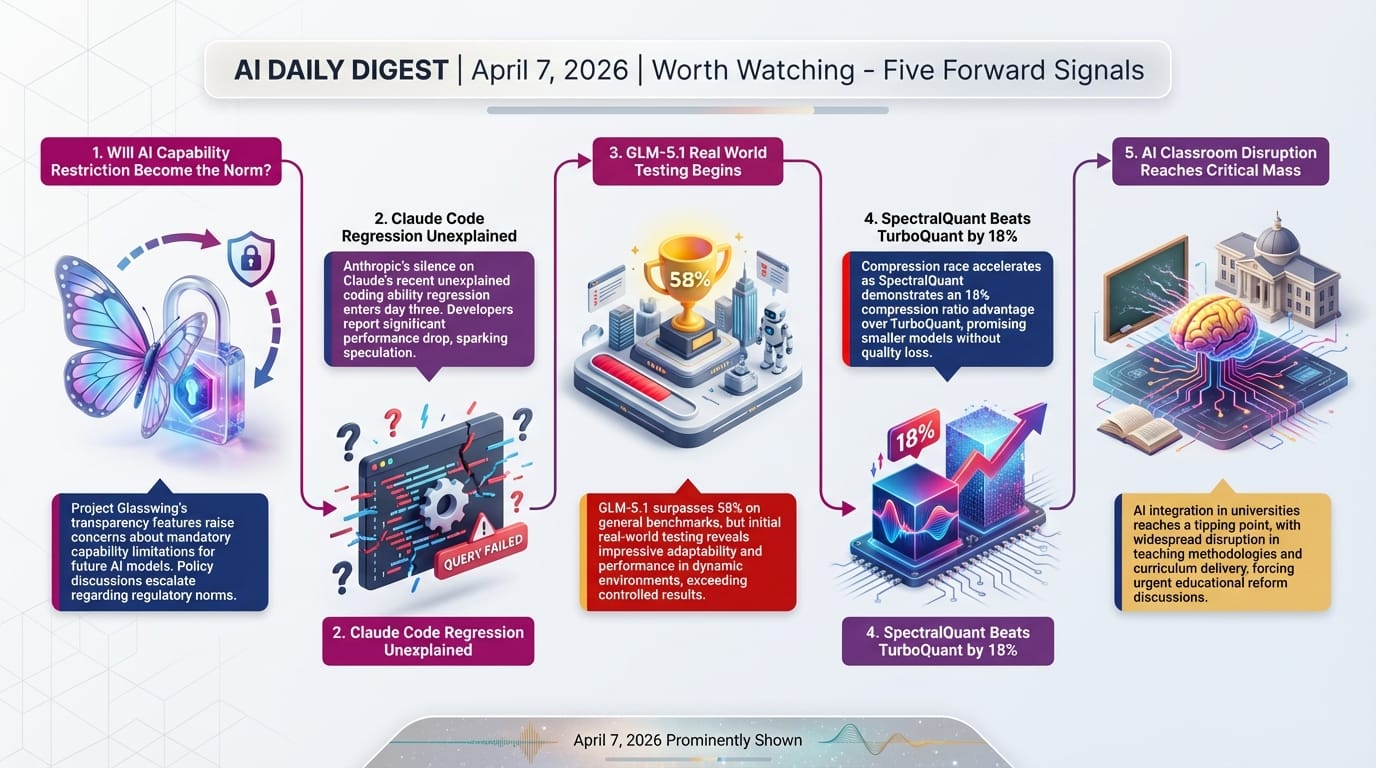
10. Worth Watching
Since earlier this week...
Gemma 4 went from a broken launch to running on phones and in 16GB RAM within 72 hours — a remarkable community-driven recovery. Claude Code was found to be reading project credential files (env files) in April 4's digest, a security concern that remains unresolved. TurboQuant appeared as the hot KV cache compression technique earlier this week — today SpectralQuant has already beaten it by 18.6%. The pace of iteration in this space is not slowing down.
1. Will Project Glasswing's restricted model approach become a template?
If other labs adopt Anthropic's model of building capability and then deliberately restricting it to vetted partners, the landscape of who has access to frontier AI changes fundamentally. Watch for other labs to either follow suit — or to use openness as a competitive differentiator.
2. The Claude Code regression still has no explanation.
Anthropic has not responded to the community's documented 67% thinking-depth drop. As this report publishes, that silence is now days old. Either an explanation or a fix would be significant. If neither comes, it sets a precedent for how AI companies handle undisclosed regressions.
3. GLM-5.1's benchmark performance on real tasks — not just SWE-Bench.
58.4% on SWE-Bench Pro is impressive for an open model, but see the SWE-EVO results: standard benchmarks may overstate real-world capability by 3x. Community testing over the next 1-2 weeks will reveal whether GLM-5.1 holds up on sustained, complex work.
4. OpenClaw and the third-party tool crackdown — how far does it go?
Anthropic restricting Claude from working with OpenClaw may be the start of a broader consolidation of how Claude is accessed. Watch whether other third-party Claude integrations get similarly affected. This has implications for the ecosystem of tools built on top of Claude's API.
5. PolySwarm and AI-driven prediction markets.
PolySwarm is a 50-persona LLM swarm — 50 AI "perspectives" that argue and synthesize — designed for prediction market trading. Combined with today's Polymarket bot story, AI-driven financial prediction is moving fast. This will matter for how markets function and who can participate in them meaningfully.
AI Daily Digest is compiled from newsletter sources, Reddit communities (r/LocalLLAMA, r/ClaudeAI, r/Professors), Hacker News, and research preprint servers. All source links are included inline. Nothing here is financial or professional advice.